Server-side tracking solves GDPR problems

Details
This article may contain outdated information as it was published 5 years ago.
Server-side tracking is a new way of collecting data from websites. The technology makes it possible to collect data in a completely anonymous way. Traditionally, measurement on websites is done by the user’s device sending data to Google Analytics with the help of cookies. In server-side tracking, however, the user’s device sends data to the site’s server, from where the data is forwarded to Analytics. This can prevent Google Analytics from ever receiving, for example, the user’s IP address. Server-side tracking allows the website owner to have complete control of what information about users is collected and what is not.

Which issue does server-side tracking solve?
Websites cannot place analytics cookies on a user’s device or collect user information until the user has given this their consent. This creates a problem: not all users give their consent, so the data collected only reflects a part of the site’s visits. User-friendly cookie banners might not disrupt the user’s browsing too much, but they also collect consent approvals poorly. In some cases, the amount of data collected on the site has dropped by as much as 80%.
Some have tried to solve the problem by creating very annoying cookie banners in order to get as many approval clicks as possible. This affects the user experience negatively, and all users still do not give their consent. Therefore in analytics, we have to settle for sample data, which makes it difficult to focus on the right things in the further development and optimization of the site.
Server-side tracking solves this problem of cookie-based tracking. The solution allows you to track events on the site without the user’s consent to cookies, as information is only collected about interactions and events that have taken place on the site. No information is collected about the user and no cookies are stored on the user’s device. No data can be tied to a particular user or to a user group.
This does not mean that cookies are no longer useful. If the user consents to the use of cookies, we can collect user data in addition to usage data. Even if server-side tracking becomes more common, cookie banners on websites will remain. Cookies can be used to collect more accurate marketing data, such as information that allows users to be profiled and divided into different user groups. Of course, if only server-side data is enough, the cookie banner can be dropped. However, most companies also want to take advantage of user data.
The difference between anonymized server-side tracking and traditional cookie-based tracking is in what data is sent to analytics and from where. If a company makes a marketing campaign based on usage data alone, it can take advantage of information such as which pages users land on, which ecommerce products are browsed the most, or which pages convert best. However, the company is not able to create user groups such as “users in Helsinki”, “users between the ages 30-40” or “users who have filled in the contact form”. Site usage data is available, but profiling information will be left out.
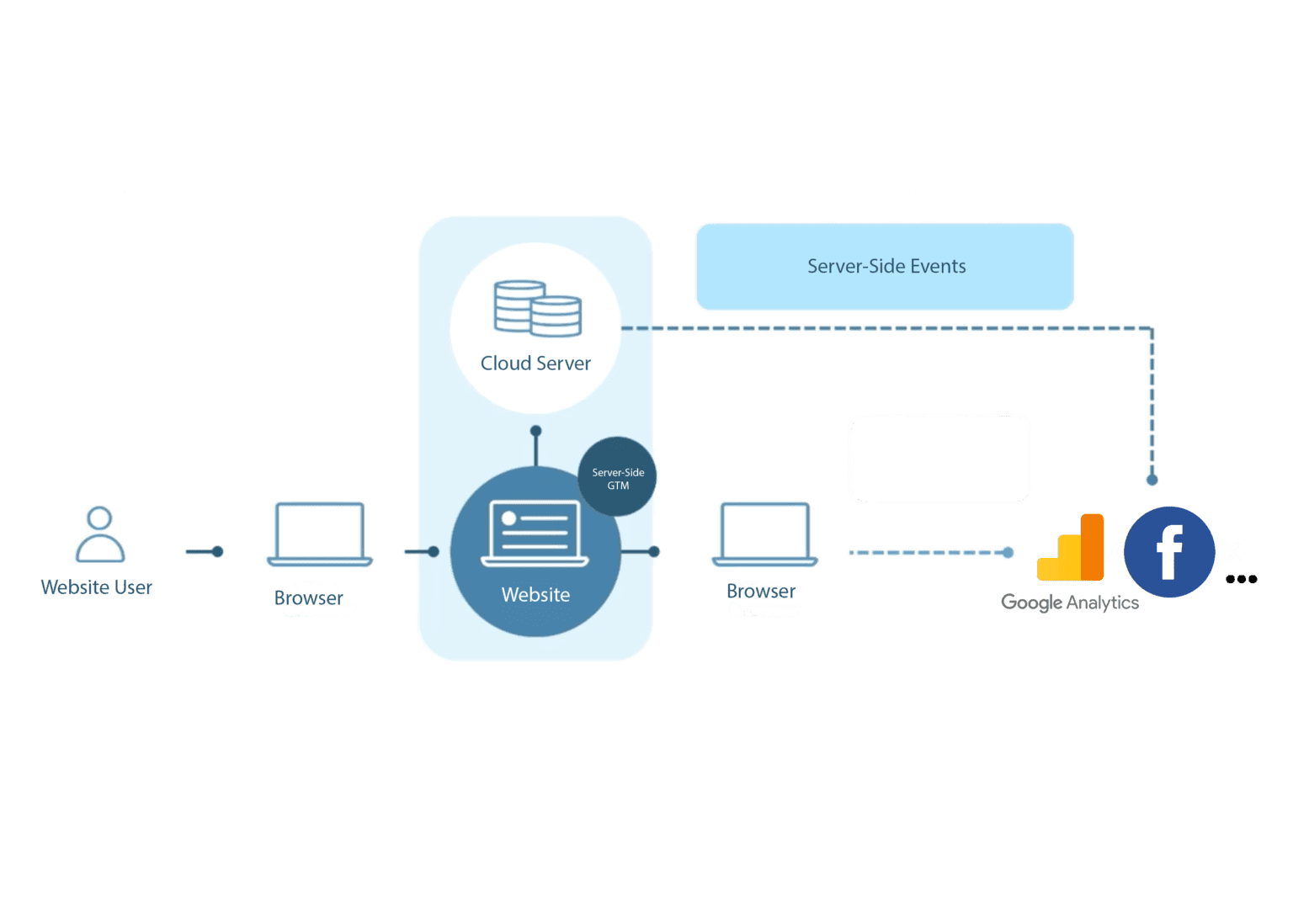
Image from here.
How does the technology work in practice?
Server-side tracking is a technology enabled by Google’s own tools that has been around for about a year. Basically, Google Tag Manager came with a feature that allows you to create a measurement using, for example, Google Cloud servers.
With Google Cloud servers, the measurement costs about 50-150 euros per month depending on the amount of traffic to the site. The price is completely dependent on the amount of data to be processed and for a very large website, the price could be as high as a couple hundred a month. However, you can generally cut a lot of extra from the processed data: for example, the price drops significantly when storing log data is turned off. It’s worth thinking carefully about which features you really need and which you can leave out.
It is also possible to run the data on your own servers, which means no additional fees for data processing. The service becomes more accessible this way, since you would only have to pay for a one-time installation instead of a monthly fee. However, this requires more manual work.
Is server-side tracking already in use on your clients’ sites?
We have successfully implemented server-side measurement for a couple of clients to a real environment. Our clients have access to all data, such as the number of users on the site, page views, and transactions just like before – but there is no need to settle for a sample, as data can be collected from all the users.
Ecommerce tracking is important to one of these clients’ businesses, so all ecommerce transactions have to be included in the data. With just cookie-based tracking in the past, consent was not obtained from all users which made the collected data less reliable. Server-side tracking has allowed user data to match actual sales and has made the data as a whole to be of higher quality.
What does the future of anonymous tracking look like?
We use server-side tracking for data anonymization, but it offers other benefits as well. Perhaps the biggest of these is the improvement in site performance. Google has recently begun to focus on Core Web Vitals, which measure a site’s user-friendliness. When data is transferred to the server, the user’s device does not have to work as hard and the site is not as burdened. This means an improved performance of the site and a better user experience.
We firmly believe that the technology will become more widespread in the coming years, as there are currently many problems with cookie-based tracking. Server-side tracking seems to be a solution capable of tackling these issues.
How is server-side tracking different from Google’s Consent mode?
Google has recently introduced Consent mode, which seeks to solve the same problems as server-side tracking, allowing data to be collected even when the user does not accept analytics cookies. Cookies used to combine data at the session and the user level are not stored. When looking at analytics, it is therefore impossible to determine whether, for example, two different page loads have taken place during the same session.
However, Consent mode works as client-side measurement, so data is transferred from the user’s device to Google Analytics. Even though data is anonymized, this may not be enough – the challenge with GDPR is not only data storage, but the fact that data in general is transmitted. In Google’s Consent mode, devices still get to know each other’s IP addresses, which poses a problem in terms of GDPR. The Consent mode is a solution that supports Google’s business, which revolves heavily around targeted advertising. Our solution of server-side tracking is purely implemented to develop websites better.
Anonymous server-side tracking allows user IDs to be created based on browser information, without that information ever being sent to analytics. The ID is not stored on the user’s device at any stage, but is created when the data is transmitted. This provides a unique identifier similar to the user ID, so user sessions can be considered consistent. The difference is that in this type of tracking, nothing is stored on the user’s device.
Anonymous server-side tracking is a more anonymous method than Consent mode and it complies with privacy settings more closely. It filters out device information and location, while in Consent mode, these are still included. For the user, this inevitably means better privacy.
Final words
With server-side tracking, you can legally do what some companies do illegally. The risk of collecting data illegally should not be taken, as the sanctions are heavy: a fine of 20 million euros or 4% of a company’s turnover can be imposed. Many break the law without knowing it: if a company does not have its own analytics team or a GDPR-savvy person, it may be hard to understand cookie settings. What also complicates the matter is the fact that data protection regulations are constantly changing. In Finland, the interpretation also depends significantly on whether you consider the stance of Traficom or the Data Protection Ombudsman.
Even if we assume that everyone complies with the law and does not collect any data from users without their permission, there is really no good reason not to introduce server-side tracking. Server-side tracking ensures that all of the site’s usage data can be collected without cookies. Cookies are still needed if you want to profile users and do data-based marketing – but if you can get information on all users without the use of cookies, why not do this?
Interested in the possibilities of server-side tracking? Contact us!